게시판을 보면 하나의 게시글에 수많은 댓글이 달림 이러한 관계를 one-to-many, 즉 일대다(1:n)관계
댓글 입장에서 보면 여러 댓글이 하나의 게시글에 달리므로 many-to-one, 즉 다대일(n:1) 관계
아래 그림을 보면 article 테이블과 comment 테이블이 id를 기준으로 관계를 맺고 있음
두 테이블 모두 자신을 대표하는 id가 있는데, id와 같이 자신을 대표하는 속성을 대표키(PK,Primary Key)라고함 (대표키는 동일 테이블 내에서 중복된 값 X)
comment 테이블에는 연관 대상을 가리키는 article_id와 같이 연관 대상을 가리키는 속성을 외래키(FK, Foreign Key)라고함 (외래키는 항상 연관된 테이블의 대표키를 가르킴)댓글과 게시글의 관계
댓글 엔티티와 리파지터리 설계
게시판 작성을 위해 Article 엔티티와 ArticleRepository 을 작성한것처럼 댓글 작성을 위해 Commenet 엔티티와 CommentRepository 을 작성
엔티티 : DB 데이터를 담는 자바 객체로, 엔티티를 기반으로 테이블 생성
리파지터리 : 엔티티를 관리하는 인터페이스로, 데이터 CRUD 등의 기능 제공
Comment 엔티티와 Article 엔티티의 다대일 관계를 설정
CommentRepository 는 JpaRepository 을 상속받아서 생성
Repository : 최상위 리파지터리 인터페이스
CrudRepository및ListCrudRepository:엔티티의 CRUD 기능 제공
PagingAndSortingRepository및ListPagingAndSortingRepository:엔티티의 페이징 및 정렬 기능 제공
JpaRepository:엔티티의 CRUD 기능과 페이징 및 정렬 기능뿐만 아니라 JPA에 특화된 기능을 추가로 제공
Comment 엔티티와 Article 엔티티의 관계
댓글 엔티티 만들기
댓글 엔티티 만들기
프로젝트의 entity 패키지 아래에 Comment.java 파일을 생성
Comment 클래스가 만들어지면 이 클래스를 엔티티로 사용한다는 @Entity을 작성 후 @Getter, @ToString, @AllArgsConstructor, @NoArgsConstructor 어노테이션도 추가
Commnet 엔티티는 id(대표키) , article(댓글의 부모 게시글), nickname(댓글을 단 사람), body(댓글 본문)으로 구성으로된 필드를 선언
id 필드에는 @Id을 붙혀 대표키임을 선언 그리고 @GeneratedValue를 붙혀 대표키를 자동으로 1씩 증가시키고 자동 생성 전략으로 strategy=GenerationType.IDENTITY을 추가해 데이터가 생성될때마다 id값이 1씩 증가하도록 설정
댓글과 게시글은 다대일 관계이기 때문에 article 필드에 @ManyToOne 어노테이션을 붙여 Comment 엔티티와 이 필드가 가르키는 Article 엔티티를 다대일 관계로 설정
article 필드에 다대일 관계를 설정 했다면 외래키 연결을 위해 @JoinColumn 어노테이션을 사용하여 name 속성으로 매핑할 외래키 이름을 지정 , 여기에서는 Article 엔티티의 id를 외래키를 지정하기에 이름을 article_id 라고 작성
nickname, body 필드에는 @Column 어노테이션을 붙여 Comment 엔티티로 만들어질 테이블의 속성으로 설정
그다음 실행하고 실행 로그에 comment 테이블이 만들어진것을 확인 가능
@Entity//해당 클래스가 엔티티임을 선언 , 클래스 필드를 바탕으로 DB에 테이블 생성@Getter// 각 필드 값을 조회할 수 있는 getter 메서드 자동 생성@ToString// 모든 필드를 출력할 수 있는 toString 메서드 자동 생성@AllArgsConstructor// 모든 필드를 매개변수로 갖는 생성자 자동 생성@NoArgsConstructor// 매개변수가 아예 없는 기본 생성자 자동 생성publicclassComment{
@Id@GeneratedValue(strategy = GenerationType.IDENTITY)// DB가 자동으로 1씩 증가private Long id; //대표키@ManyToOne//Comment 엔티티와 Article 엔티티를 다대일 관계로 설정@JoinColumn(name = "article_id")// 외래키 생성, Article 엔티티의 기본키(id)와 매칭private Article article; //해당 댓글의 부모 게시글@Column//해당 필드를 테이블의 속성으로 매핑private String nickname; // 댓글을 단 사람@Column//해당 필드를 테이블의 속성으로 매핑private String body; // 댓글 본문
}
실행 로그을 보면 테이블을 생성하고 article와 외래키 연결H2 에도 테이블 생성되어있음
더미 데이터 추가하기
data.sql 파일에서 더미 데이터 추가
article 테이블과 comment 테이블의 데이터 추가
comment 테이블에는 article 테이블과 연결하는 외래키가 있으므로 해당 게시물의 id를 입력하기
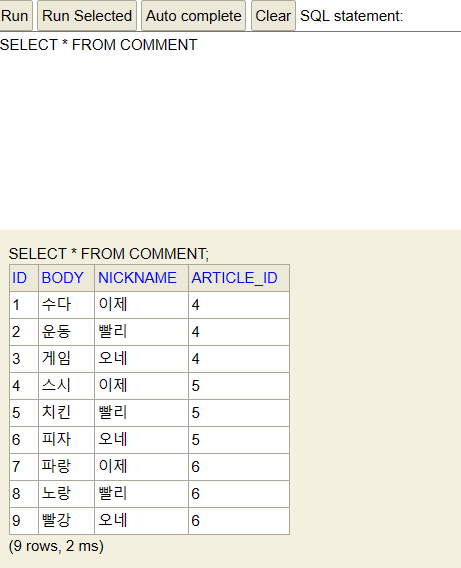
서버를 다시 시작하고 테이블을 조회하면 데이터 삽입됨
//data.sql INSERT INTO article(title, content)VALUES('당신의 취미는?', '댓글 작성해 주세요');
INSERT INTO article(title, content)VALUES('당신이 좋아하는 음식은?', '댓글 작성해 주세요');
INSERT INTO article(title, content)VALUES('당신의 좋아하는 색깔은?', '댓글 작성해 주세요');
INSERT INTO comment(article_id,nickname, body)VALUES(4, '이제', '수다');
INSERT INTO comment(article_id,nickname, body)VALUES(4, '빨리', '운동');
INSERT INTO comment(article_id,nickname, body)VALUES(4, '오네', '게임');
INSERT INTO comment(article_id,nickname, body)VALUES(5, '이제', '스시');
INSERT INTO comment(article_id,nickname, body)VALUES(5, '빨리', '치킨');
INSERT INTO comment(article_id,nickname, body)VALUES(5, '오네', '피자');
INSERT INTO comment(article_id,nickname, body)VALUES(6, '이제', '파랑');
INSERT INTO comment(article_id,nickname, body)VALUES(6, '빨리', '노랑');
INSERT INTO comment(article_id,nickname, body)VALUES(6, '오네', '빨강');
더미데이터 추가 성공
댓글 리파지터리 만들기
프로젝트의 repository 패키지에 CommentRepository 라는 interface 자바파일 생성
JpaRepository 인터페이스를 상속받는데 Comment 엔티티를 관리하므로 대상 엔티티에는 Comment, 대표키 값의 타입에는 id의 타입인 Long을 넣음
형식 : JpaRepository<대상_엔티티 , 대표키_값의_타입>
JPA 에서 단순한 CRUD 작업만 하면 CrudRepository를 충분하지만 CURD 작업과 페이지 처리와 정렬 작업까지 해야하면 JpaRepository를 사용하는것이 좋음
네이티브 쿼리 메서드(native query method)를 사용해서 쿼리 작성
네이티브 쿼리 메서드는 직접 작성한 SQL 쿼리를 리파지터리 메서드로 실행할 수 있도록 함
네이티브 쿼리 메서드를 만드는 방법은 2가지 있음
@Query 어노테이션을 사용하는 방법
orm.xml 파일을 이용한 방법
특정 게시글의 모든 댓글 조회
특정 게시글의 모든 댓글을 조회 하는 메서드 이름을 findByArticleId로 작성후 메서드의 매개변수로 articleId를 받고 이 메서드의 실행 결과로 댓글의 묶음을 반환할 테니 반환형은 List<Comment>로 작성
findByArticleId()메서드로 원하는 쿼리를 수행하기 위해 @Query 어노테이션 작성
@Query(value = "쿼리" , nativeQuery = true) 이런 형식으로 작성
@Query는 SQL 과 유사한 JPQL이라는 객체지향 쿼리 언어를 통해 복잡한 쿼리 처리를 지원
@Query에 nativeQuery속성을 true 로 설정하면 기존 SQL 문을 그대로 사용가능
여기서는 JPQL 대신 SQL 문을 사용
@Query을 사용해 SQL문을 사용할때 WHERE 절에 조건을 쓸 때 매개변수 앞에는 꼭 클론(:)을 붙여 줘야 함 그래야지 메서드에서 넘긴 매개변수와 매칭 가능
특정 닉네임의 모든 댓글 조회
특정 닉네임의 모든 댓글을 조회하는 메서드 이름을 findByNickname로 작성후 매개변수로 nickname를 받고 이 메서드의 실행 결과로 댓글의 묶음을 반환할 테니 반환형은 List<Comment>로 작성
findByNickname() 메서드 에서 수행할 쿼리를 XML로 작성
이러한 XML을 네이티브 쿼리 XML (native query XML)이라고 함
네이티브 쿼리 XML의 기본 경로와 파일 이름은 resources 아래에 META-INF 디렉터리를 새로 생성후 META-INF안에 orm.xml이라는 파일 생성
<entity-mappings> 태그 안에 <named-native-query>와 <query> 태그를 이용해 쿼리를 입력
이와 같은 형식으로 입력
<named-native-query
name="쿼리_수행_대상_엔티티.메서드_이름"
result-class="쿼리_수행_결과_반환하는_타입의_전체_패키지_경로">
<query>
<![CDATA[
<!-- 실제 수행할 쿼리 -->
<!-- Character DATA, 즉 파싱(구문 분석)되지 않은 문자 데이터를 쓸 때 사용
이 구문을 사용해야지 SQL 문의 값의 대소 비교 연산등에 문제가 생기지 않음
-->
]]>
</query>
</named-native-query>
서버를 재시작 하여 문제가 없는지 확인
CommentRepository.java 파일
publicinterfaceCommentRepositoryextendsJpaRepository<Comment, Long> {
// 특정 게시글의 모든 댓글 조회//@Query(value =// "SELECT * " +// "FROM comment " +// "WHERE article_id = :articleId", // nativeQuery = true) 이렇게 +연산자로 작성도 가능 @Query(value = "SELECT * FROM comment WHERE article_id = :articleId" , nativeQuery = true)// value 속성에 실행하려는 쿼리 작성List<Comment> findByArticleId(Long articleId);
// 특정 닉네임의 모든 댓글 조회List<Comment> findByNickname(String nickname);
}
========================================
resources\META-INF\orm.xml 파일
<?xml version="1.0" encoding="utf-8" ?>
<entity-mappings xmlns="https://jakarta.ee/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence/orm
https://jakarta.ee/xml/ns/persistence/orm/orm_3_0.xsd"
version="3.0">
<named-native-query
name="Comment.findByNickname"
result-class="com.example.firstproject.entity.Comment">
<query>
<![CDATA[
SELECT * FROM comment WHERE nickname = :nickname
]]>
</query>
</named-native-query>
</entity-mappings>
댓글 리파지터리 테스트 코드 작성하기
src/java/test 디렉터리 아래에있는 프로젝트에 repository 패키지 생성후 CommentRepositoryTest 생성
테스트 코드의 기본 설정 하기
ArticleService를 테스트 했을 때는 @SpringBootTest 어노테이션을 붙여 스프링 부트와 연동한 테스트를 진행하였으나 이번에는 리파지터리를 테스트 하므로 @DataJpaTest 어노테이션을 붙임
@DataJpaTest는 해당 클래스를 JPA와 연동해 테스트하겠다는 선언
CommentRepository를 테스트하기 위해 commentRepository 객체를 선언하고 외부의 객체를 주입해야 하므로 @Autowired도 작성
findByArticleId() 테스트
메서드 명을 바꾸지 않고 @DisplayName 어노테이션을 사용
@DisplayName("테스트_결과에_보여줄_이름") 형식으로 작성
기본적으로 테스트 이름은 메서드 이름을 따라가는데 @DisplayName을 사용하여 테스트 이름을 붙힘
테스트 케이스를 여러 개 작성할 것이므로 테스트 마다 중괄호({})로 묶고 테스트 단계를 주석으로 써둠
입력 데이터 준비
실제 데이터
예상 데이터
비교 및 검증
2단계 실제 데이터에 commentRepository.findByArticleId(articleId) 메서드를 호출해 얻은 결과를 comments 리스트에 저장
1단계 입력 데이터 준비에서는 조회할 게시글의 id(여기서는 4)를 적어둠
4단계 비교 및 검증에 assertEquals() 메서드로 예상 데이터 문자열(expected.toString())과 실제 데이터의 문자열(comments.toString())이 같은지 비교, 메서드의 마지막 전달값으로는 검증이 실패했을 때 출력할 메시지를 넣음
3단계 예상 데이터를 작성
comment 테이블에 조회할 게시글의 id의 댓글을 Comment a,b,c 객체에 저장
a, b, c 객체의 두번째 필드는 부모 게시글인 article 이기에 article 객체도 생성
a, b, c 객체를 하나의 리스트로 합치고 이를 expected 리스트에 저장
테스트 실행해보기
계속 에러가 발생해서 main 패키지 안에 있는 CommentRepository 파일안에 @Query(value = "SELECT * FROM comment WHERE article_id = :articleId" , nativeQuery = true) List<Comment> findByArticleId(@Param("articleId")Long articleId); 으로 수정
다른 방법
프로젝트 우클릭 → Properties 선택.
"Java Compiler" → "JDK Compliance"로 이동.
"Enable project specific settings" 체크.
"Store information about method parameters (usable via reflection)" 옵션 선택.
package com.example.firstproject.repository;
importstatic org.junit.jupiter.api.Assertions.assertEquals;
import java.util.Arrays;
import java.util.List;
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import com.example.firstproject.entity.Article;
import com.example.firstproject.entity.Comment;
@DataJpaTest// 해당 클래스를 JPA와 연동해 테스팅publicclassCommentRepositoryTest{
@Autowired
CommentRepository commentRepository; // commentRepository 객체 주입@Test@DisplayName("특정 게시글의 모든 댓글 조회")voidfindByArticleId(){
/* Case 1: 4번 게시글의 모든 댓글 조회 */
{
// 1. 입력 데이터 준비
Long articleId = 4L; // 조회할 id// 2. 실제 데이터
List<Comment> comments = commentRepository.findByArticleId(articleId);
// 3. 예상 데이터
Article article = new Article(4L, "당신의 취미는?", "댓글 작성해 주세요"); //부모 게시글 객체 새성
Comment a = new Comment(1L, article, "이제", "수다"); //댓글 객체 생성
Comment b = new Comment(2L, article, "빨리", "운동"); //댓글 객체 생성
Comment c = new Comment(3L, article, "오네", "게임"); //댓글 객체 생성
List<Comment> expected = Arrays.asList(a,b,c); //댓글 객체 합치기// 4. 비교 및 검증
assertEquals(expected.toString(), comments.toString() , "4번 글의 모든 댓글을 출력!" );
}
/* Case 2: 1번 게시글의 모든 댓글 조회 */
{
// 1. 입력 데이터 준비
Long articleId = 1L; // 조회할 id// 2. 실제 데이터
List<Comment> comments = commentRepository.findByArticleId(articleId);
// 3. 예상 데이터
Article article = new Article(1L, "가가가가", "1111"); //부모 게시글 객체 새성
List<Comment> expected = Arrays.asList();
// 4. 비교 및 검증
assertEquals(expected.toString(), comments.toString() , "1번 글의 댓글이 없음" );
}
}
}
테스트 통과
findByNickname() 테스트
@DisplayName으로 테스트 이름을 설정
첫번째 테스트 케이스로 이제의 모든 댓글을 조회 . 테스트 케이스를 중괄호로 묶고 테스트 단계를 주석으로 써둠
실제 데이터를 가져오기위해 commentRepository.findByNickname(nickname) 메서드를 호출해 얻은 결과를 comments 리스트에 저장
입력 데이터에는 이제가 쓴 모든 댓글을 조회함므로 nickname에 "이제" 을 넣음
"이제" 가 작성한 댓글 데이터를 Comment a, b, c 객체에 저장 그런데 각각 댓글의 부모 articleid가 다르기에 하나의 article 객체를 만들어 참조 할수 없으므로 각각 article 필드에 객체를 생성
assertEquals() 메서드로 예상 데이터의 문자열(expected.toString())과 실제 데이터의 문자열(comments.toString())이 같은지 비교하고 검증에 실패할 경우 보여 줄 메시지 입력
테스트 실행하기
@Test@DisplayName("특정 닉네임의 모든 댓글 조회")voidfindByNickname(){
/* Case 1: "이제"의 모든 댓글 조회 */
{
// 1. 입력 데이터 준비
String nickname = "이제";
// 2. 실제 데이터
List<Comment> comments = commentRepository.findByNickname(nickname);
// 3. 예상 데이터
Comment a = new Comment(1L, new Article(4L, "당신의 취미는?", "댓글 작성해 주세요"), nickname, "수다"); //댓글 객체 생성(부모 객체는 각 필드에 따로 생성)
Comment b = new Comment(4L, new Article(5L, "당신이 좋아하는 음식은?", "댓글 작성해 주세요"), nickname, "스시");
Comment c = new Comment(7L, new Article(6L, "당신의 좋아하는 색깔은?", "댓글 작성해 주세요"), nickname, "파랑");
List<Comment> expected = Arrays.asList(a,b,c); //댓글 객체 합치기// 4. 비교 및 검증
assertEquals(expected.toString(),comments.toString(), "이제의 모든 댓글을 출력!" );
}
}